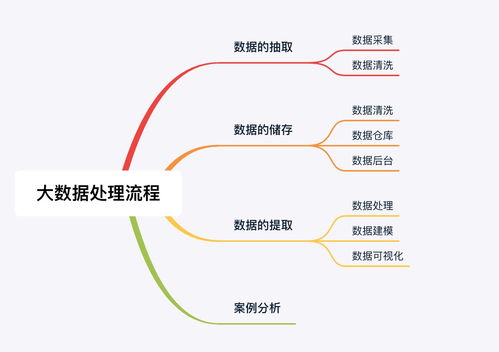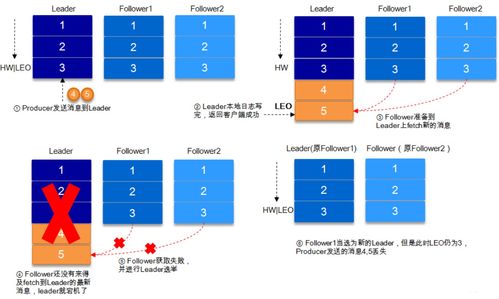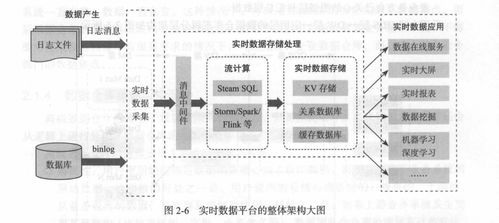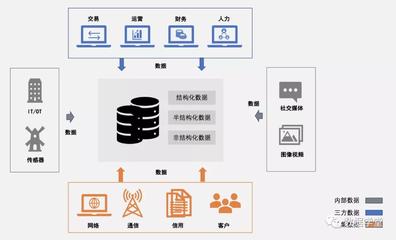
在当今数字化浪潮中,数据处理与存储已成为技术发展的核心支柱。开源项目、代码、文档、新闻及社区共同构成了一个强大的“深度开源”生态系统,推动着数据处理与存储技术的创新与普及。本文将探讨这一生态如何协同作用,并分析其对行业的影响与未来趋势。
一、开源项目:技术创新的引擎
开源项目是数据处理与存储领域的基石。例如,Apache Hadoop和Apache Spark为大数据处理提供了分布式计算框架,而PostgreSQL和MySQL则在关系型数据库领域占据主导地位。云原生数据库如CockroachDB和时序数据库如InfluxDB也通过开源模式迅速崛起。这些项目不仅降低了技术门槛,还通过社区协作不断优化性能,支持从企业级应用到物联网场景的多样化需求。
二、开源代码:透明与协作的实践
开源代码的核心在于其透明性和可访问性。开发者可以自由查看、修改和分发代码,这加速了bug修复和功能迭代。在数据处理领域,代码开源促进了标准化进程,例如Apache Arrow为跨语言数据交换提供了统一格式。开源许可协议(如GPL、Apache 2.0)确保了知识共享的合法性,鼓励企业贡献回馈,形成良性循环。
三、开源文档:知识传播的桥梁
高质量的文档是开源项目成功的关键。它帮助用户快速上手,降低学习曲线。例如,Kubernetes的官方文档详细阐述了容器编排的最佳实践,而TensorFlow的教程则推动了机器学习普及。社区驱动的文档平台(如Read the Docs)允许用户共同编辑,确保信息的时效性和准确性。开源文档不仅服务于技术实施,还成为教育培训的重要资源。
四、开源新闻:动态与趋势的窗口
开源新闻平台(如OSChina、开源中国)和社区博客实时追踪技术动态,发布版本更新、安全漏洞通知及行业案例分析。这些信息流帮助开发者保持敏锐,把握数据处理存储领域的最新进展,如量子计算数据库的探索或边缘存储方案的演进。通过新闻传播,开源理念得以广泛宣传,吸引更多参与者加入生态。
五、开源社区:协作与文化的熔炉
开源社区是生态系统的灵魂。从邮件列表到GitHub Issues,从线下Meetup到全球峰会(如FOSDEM),社区提供了交流合作的平台。在数据处理存储领域,社区成员包括开发者、用户和研究者,他们通过代码审查、讨论论坛和贡献指南共同推动项目发展。例如,Apache软件基金会的治理模式确保了项目的长期可持续性,而新兴社区如CNCF(云原生计算基金会)则专注于云原生存储方案(如Rook)。社区文化强调开放、包容和共享,这培养了创新精神并解决了复杂技术挑战。
六、数据处理与存储的融合实践
深度开源生态正驱动数据处理与存储的深度融合。以数据湖仓一体(Lakehouse)为例,开源项目Delta Lake和Apache Iceberg通过元数据管理实现了数据湖与数据仓库的优势结合。在存储层面,Ceph和MinIO提供了可扩展的对象存储解决方案,支持多云环境。这些技术通过开源模式快速迭代,适应了实时分析和AI工作负载的需求。
七、挑战与未来展望
尽管开源生态蓬勃发展,但仍面临挑战:如安全风险(如供应链攻击)、商业化与开源的平衡,以及技术碎片化问题。随着数据量的爆炸增长,开源社区需关注绿色计算和隐私保护,发展更高效的数据压缩算法和加密存储方案。AI驱动的自动化运维工具(如Prometheus for监控)将进一步提升生态的成熟度。
深度开源不仅是一种技术模式,更是一场协作革命。在数据处理与存储领域,它通过项目、代码、文档、新闻和社区的立体互动,赋能全球创新。企业和个人应积极参与其中,共同塑造一个更加开放、智能的数据未来。