在当今数字化的时代,大数据已成为驱动社会进步和科技创新的核心要素。无论是智能推荐、医疗诊断,还是城市规划、气候预测,背后都离不开海量数据的支撑。这些用于处理和分析的庞大数据究竟从何而来?它们又是如何被收集、存储并最终转化为有价值的信息的?本文将深入浅出地探讨大数据处理的源头及其与数据处理、存储的紧密关系。
一、大数据的主要来源
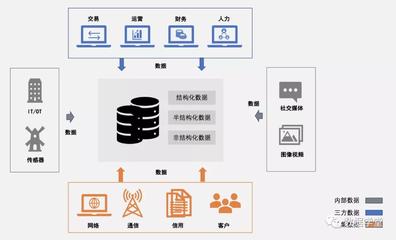
大数据的来源极为广泛,几乎涵盖了人类活动和自然世界的各个方面。可以归纳为以下几个主要渠道:
- 互联网与社交媒体:这是数据量最大、增长最快的来源之一。包括:
- 用户生成内容(UGC):我们在社交媒体(如微博、微信、抖音)上发布的文字、图片、视频、点赞、评论和转发。
- 网络行为数据:在搜索引擎的查询记录、电商平台的浏览与购买历史、新闻APP的点击流、视频网站的观看记录等。
- 服务日志:各类网站、应用程序、服务器在运行过程中自动产生的日志文件,记录了每一次访问的详细信息。
- 物联网(IoT):随着传感器和智能设备的普及,物理世界正在被全面数字化。数据来源包括:
- 智能硬件:智能手机的GPS位置、运动传感器数据;智能手环/手表采集的心率、睡眠、步数等健康数据。
- 工业物联网:生产线上的传感器实时监测设备状态、温度、压力、振动;智能电表、水表记录资源消耗。
- 智慧城市:交通摄像头、环境监测站、智能路灯等公共设施产生的视频流和环境数据。
- 传统企业与组织机构:这是历史悠久且结构化的数据来源。
- 业务交易数据:银行、保险、零售业的交易记录、财务报表、客户信息等。
- 医疗健康数据:医院的电子病历、医学影像(CT、MRI)、基因组学数据、可穿戴设备上传的健康信息。
- 科研数据:大型科学实验(如粒子对撞机、天文望远镜)、气候模拟、生物信息学研究产生的超大规模数据集。
- 公共与开放数据:由政府、研究机构等公开提供的数据集,用于促进透明度和创新。
- 政府公开数据:人口普查数据、经济统计数据、地理信息系统(GIS)数据、气象数据等。
- 开源数据集:学术界和科技公司为促进研究而公开的数据集,如ImageNet(图像识别)、Common Crawl(网页抓取数据)等。
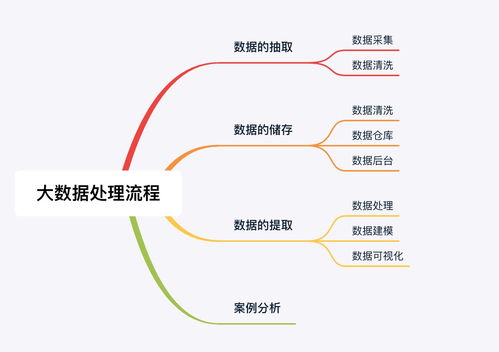
二、从数据源头到处理与存储的流程
原始数据如同未经提炼的矿石,需要经过一系列环节才能变成有价值的“信息金矿”。这个过程主要包含采集、存储、处理和分析几个关键阶段。
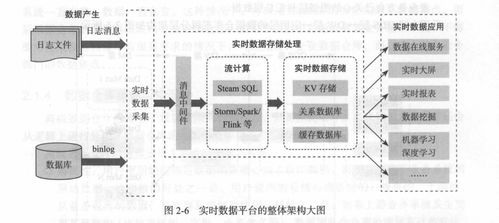
- 数据采集与摄取:
- 这是第一步,目标是将数据从源头“搬”到数据系统中。技术手段多样,包括:
- 网络爬虫:从互联网上自动抓取网页内容。
- 传感器数据流:通过消息队列(如Kafka)实时接收物联网设备上传的数据流。
- 日志收集器(如Flume, Logstash):集中采集分布在各服务器上的日志文件。
- 数据库同步:将传统业务数据库的数据导出或实时同步到大数据平台。
- 数据存储:
- 海量、多样、高速增长的数据对存储提出了巨大挑战。大数据存储的核心思想是分布式存储,即使用成百上千台普通服务器组成集群来共同保存数据。主流技术包括:
- 分布式文件系统:如Hadoop HDFS,适合存储超大文件,并提供高容错性。
- NoSQL数据库:如HBase、Cassandra、MongoDB,它们放弃了传统关系型数据库严格的一致性要求,以换取更好的可扩展性和灵活性,擅长处理半结构化和非结构化数据。
- 云对象存储:如Amazon S3、阿里云OSS,提供了几乎无限的存储空间,通过简单的API进行访问,成本低廉,是存储海量冷数据(不常访问)的理想选择。
- 存储时,还需考虑数据的分层(热数据、温数据、冷数据),以优化成本和访问效率。
- 数据处理与分析:
- 这是大数据的“炼金”阶段,目标是从存储的数据中提取洞见、发现规律、预测趋势。处理模式主要分为两类:
- 批处理:对一段时间内积累的大量数据进行离线计算,速度较慢但吞吐量大、分析深入。代表框架是Hadoop MapReduce及其之上的Hive、Spark等。常用于历史数据分析、报表生成。
- 流处理:对连续不断产生的数据流进行实时或近实时的计算,延迟极低。代表框架是Apache Flink、Spark Streaming、Storm。常用于实时监控、欺诈检测、实时推荐等场景。
- 数据在分析前通常需要经过数据清洗、集成、转换等预处理步骤,以确保数据质量。
三、一个生生不息的循环
大数据的生态系统是一个动态、闭环的循环:
数据来源(源头) → 采集与摄取(搬运) → 分布式存储(仓库) → 处理与分析(炼金厂) → 产生洞见与价值(产品) → 指导行动/产生新数据(新源头)
例如,一个电商平台的推荐系统,其数据来源于用户的点击和购买行为(源头),这些行为被实时采集并存储于大数据平台(存储),通过流处理和机器学习模型进行分析(处理),实时生成个性化推荐列表(价值),用户看到推荐后再次点击或购买,又产生了新的数据,如此循环往复,不断优化。
因此,理解大数据从何而来,是理解其整个处理与存储逻辑的基石。正是这些来自四面八方、看似杂乱无章的原始数据,经过现代计算技术的精心梳理和提炼,最终汇聚成驱动智能时代的强大动力。