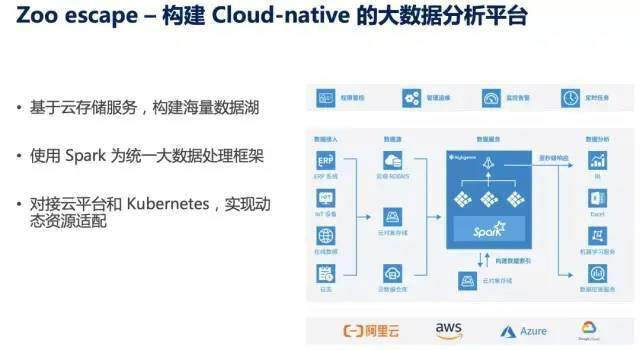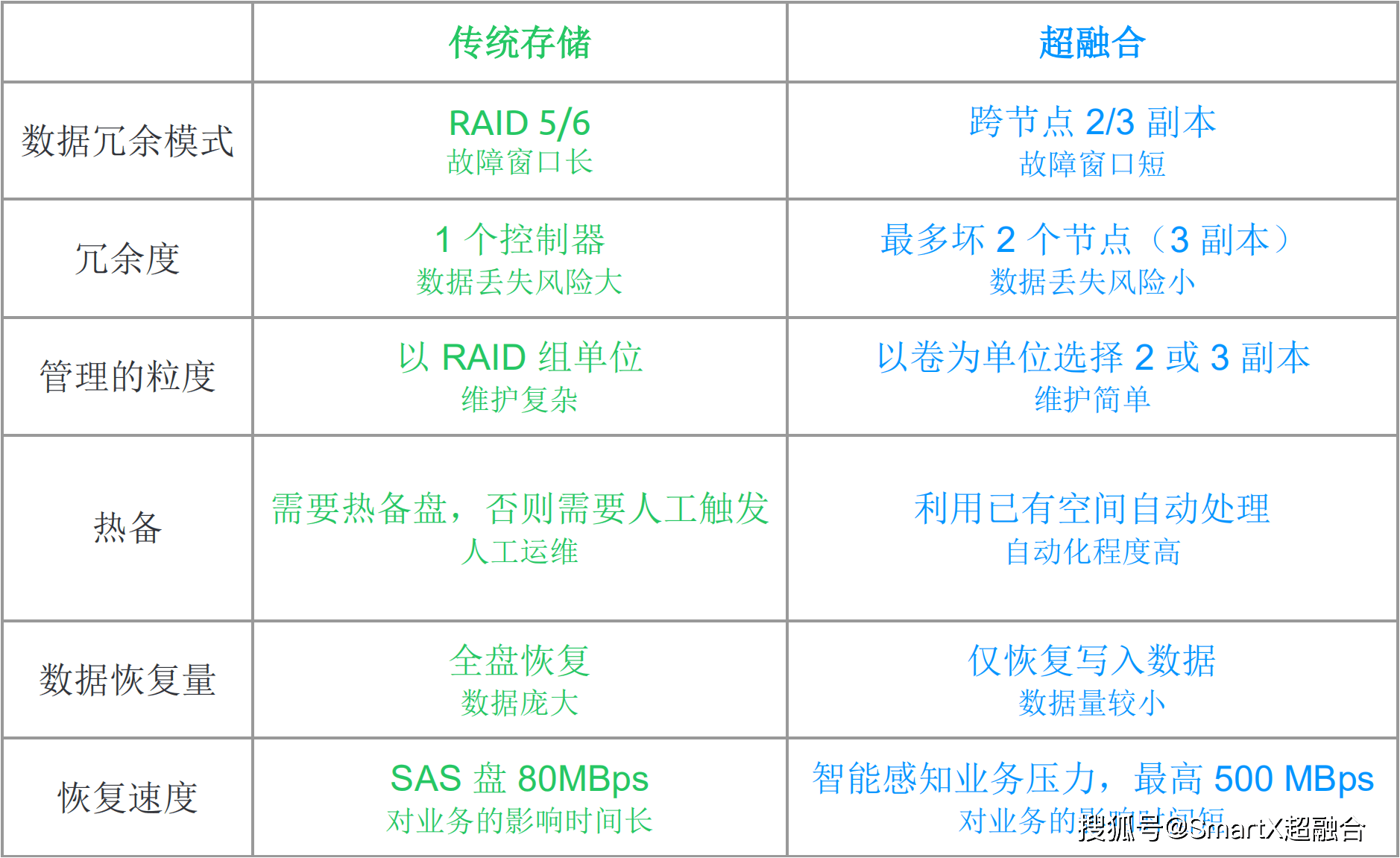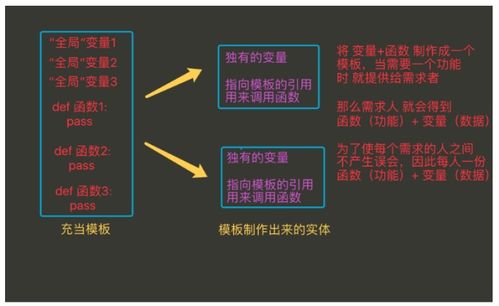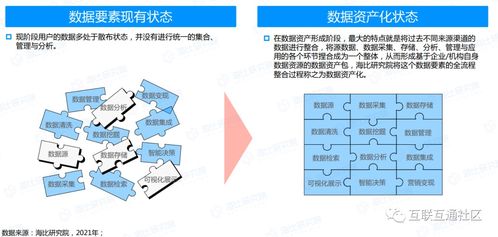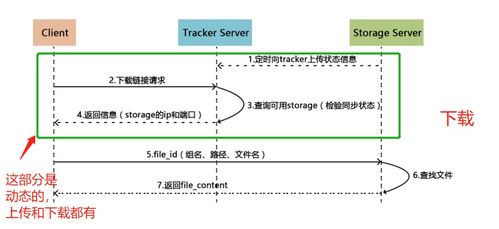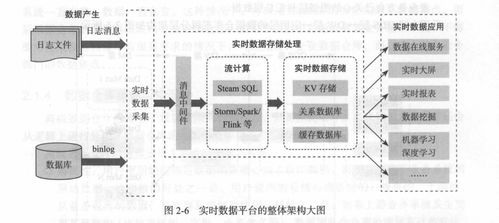
在阅读《离线和实时大数据开发实战》一书的过程中,我对其关于数据处理与存储的论述有了较为深刻的理解。该书系统性地阐述了在大数据场景下,如何高效、可靠地处理与存储海量数据,这不仅是技术挑战,更是架构设计的艺术。
一、数据处理的双轨制:离线与实时
书中明确指出,现代大数据处理已形成离线和实时两大并行体系。离线处理(如基于Hadoop MapReduce、Hive的批处理)适用于对时效性要求不高、但需复杂计算与全量分析的业务场景,其核心在于吞吐量与成本优化。而实时处理(如基于Apache Flink、Apache Storm的流计算)则应对瞬息万变的业务需求,如实时监控、风险预警,其灵魂是低延迟与高可用。两者并非替代关系,而是互补共存,共同构成企业数据驱动的双引擎。书中通过实际案例,详细对比了两种模式在架构设计、资源调度、容错机制上的异同,令人印象深刻。
二、数据存储的分层与选型
在存储层面,本书强调了根据数据热度、访问模式、一致性要求进行分层存储的重要性。从高速缓存(如Redis)、分布式文件系统(如HDFS)、NoSQL数据库(如HBase、Cassandra)到数据仓库(如Hive、ClickHouse),每一种存储介质都有其特定的适用场景。书中特别指出,数据湖与数据仓库的融合趋势日益明显,原始数据的低成本存储与结构化数据的高效查询需在架构上得到平衡。对于实时数据流,消息队列(如Kafka)不仅作为数据传输的管道,其持久化机制也成为了流处理存储设计的关键一环。
三、实战中的挑战与应对
理论终需落地。书中用了大量篇幅探讨实战中常见的问题:如何保证数据在离线和实时链路中的一致性(Lambda架构与Kappa架构的抉择)?如何设计可扩展的存储 schema 以应对业务快速变化?如何优化数据倾斜带来的处理瓶颈?作者结合自身经验,给出了具体的调优策略、监控指标与故障排查思路,极具参考价值。例如,通过压缩算法、列式存储提升I/O效率;通过窗口函数、状态管理优化流处理逻辑;通过元数据管理、数据血缘保障数据质量与治理。
四、未来展望
随着云原生、存算分离、湖仓一体等概念的兴起,数据处理与存储的边界正在变得模糊,技术栈也在不断演进。本书在最后也前瞻性地指出,未来的系统将更加强调弹性伸缩、自动化运维与智能优化。作为开发者,我们不仅要掌握当前主流框架,更需理解其背后的设计哲学,方能以不变应万变。
这本《离线和实时大数据开发实战》为我系统化理解大数据核心环节——数据处理与存储提供了清晰的蓝图。它不仅是工具手册,更是架构思想指南,提醒我们在纷繁的技术选型中,始终要回归业务本质:数据如何高效、准确地转化为价值。